Today, I’ve read a paper about anotation.
The title is "Crowdsourcing Annotations for Visual Object Detection".
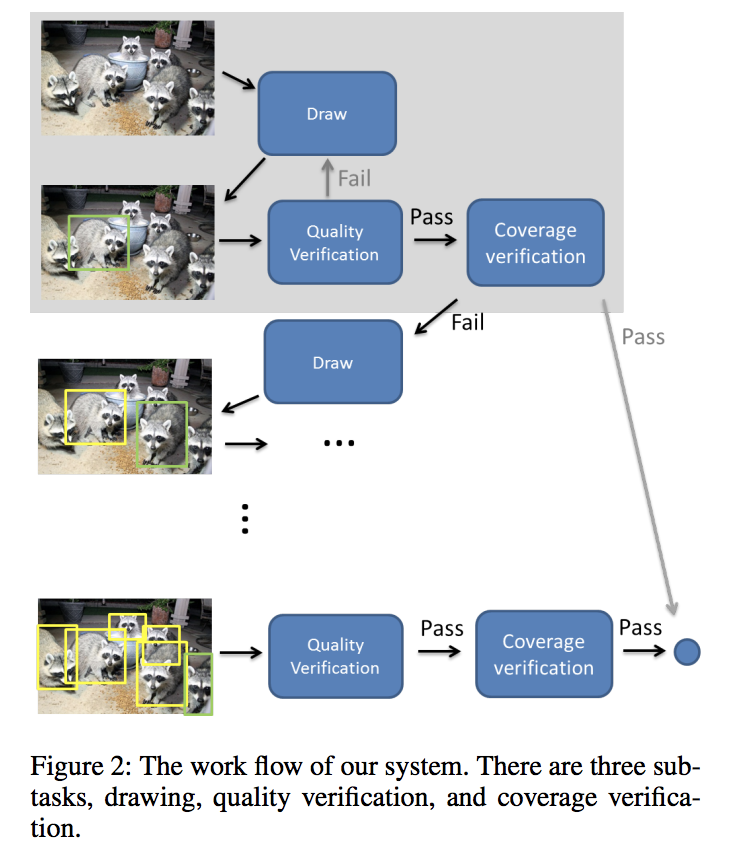
What it is doing isn’t super new, just saying that dividing annotation work into three parts will save time as well as improve accuracy.
- Drawing: A worker draws one bounding box around one instance of the given image.
- Quality verification: A second worker verifies whether a bounding box is correctly drawn.
- Coverage verification: A third worker verifies whether all object instances have bounding boxes.
The architecture of their task division goes like this.
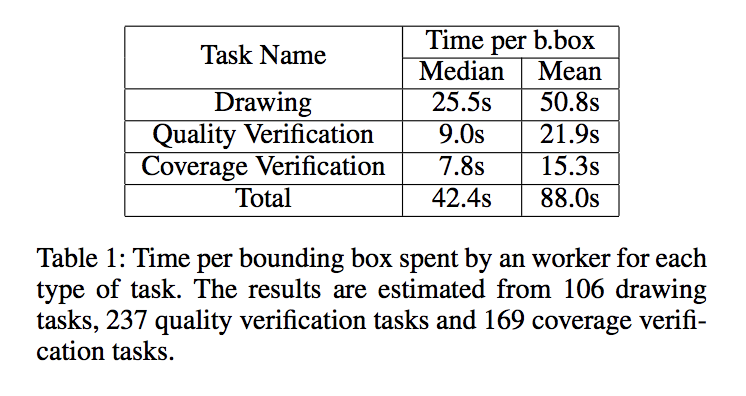
The results are kind of obvious, but I’ll post them.